NEUROSYMBOLIC AI
Neurosymbolic AI is a branch of artificial intelligence that combines the ability of machine learning to uncover complex patterns in data with the interpretability
and structured reasoning of symbolic AI.
This hybrid approach is particularly valuable in domains like healthcare, where data is often scarce due to legal restrictions
and the limited digitalization of medical facilities. Furthermore, available data may reflect existing social dynamics and inequalities, potentially leading to biased
outcomes that compromise fairness in medical treatment.
In such contexts, regulations like the GDPR require that decisions affecting patients be explainable and justified, something that is particularly challenging for
complex machine learning models, such as neural networks, which rely on algebraic and differential operations that are not easily interpretable by humans.
Additionally, these models are not guaranteed to align with established medical guidelines, raising ethical and legal concerns that discourage their adoption.
Neurosymbolic AI can help address these challenges by incorporating techniques for knowledge injection and extraction. By explicitly encoding symbolic knowledge,
such as medical guidelines or ethical constraints, it becomes possible to represent underrepresented or misrepresented situations within the data, guiding models
during training to behave more fairly and reliably. In addition, knowledge extraction techniques can be used to derive symbolic representations from trained models,
enabling clearer explanations of the reasoning behind their decisions. This makes neurosymbolic AI a promising approach for building AI systems that are both
powerful and trustworthy, especially in high-stakes fields like healthcare.
SYMBOLIC KNOWLEDGE INJECTION
Symbolic Knowledge Injection is the procedure of integrating structured knowledge into machine learning models using various formal representations such as
propositional logic, first-order logic, Horn clauses, modal logic, and other symbolic frameworks, in order to make the model consistent with the given knowledge.
This serves to guide learning, improve generalization, ensure consistency with domain knowledge, and enhance the interpretability of the resulting models.
In this study, three existing SKI methods were evaluated: KBANN, KINS, and LTN.
KBANN (Knowledge-Based Artificial Neural Networks) creates a neural network architecture directly from symbolic knowledge, typically in the form
of logical rules, and uses it as the starting point for learning. KINS (Knowledge Injection via Network Structuring) modifies an existing neural network by adding neurons and connections derived from symbolic knowledge, so that
the architecture becomes consistent with domain-specific rules. LTN (Logic Tensor Networks) adopts a guided learning approach that uses computational graphs to
evaluate the consistency between the model and the injected knowledge, incorporating this consistency into the loss function to steer the training process.
🌟SIAMESE TRAINING INJECTION🌟
This method leverages the siamese training method, that allows to train the network simultaneously on both the data and the symbolic knowledge.
Siamese training involves the use of two (or more) identical neural networks that share the same architecture and weights.
Each network processes a different type of input - in this case, one receives raw data and the other receives symbolic knowledge.
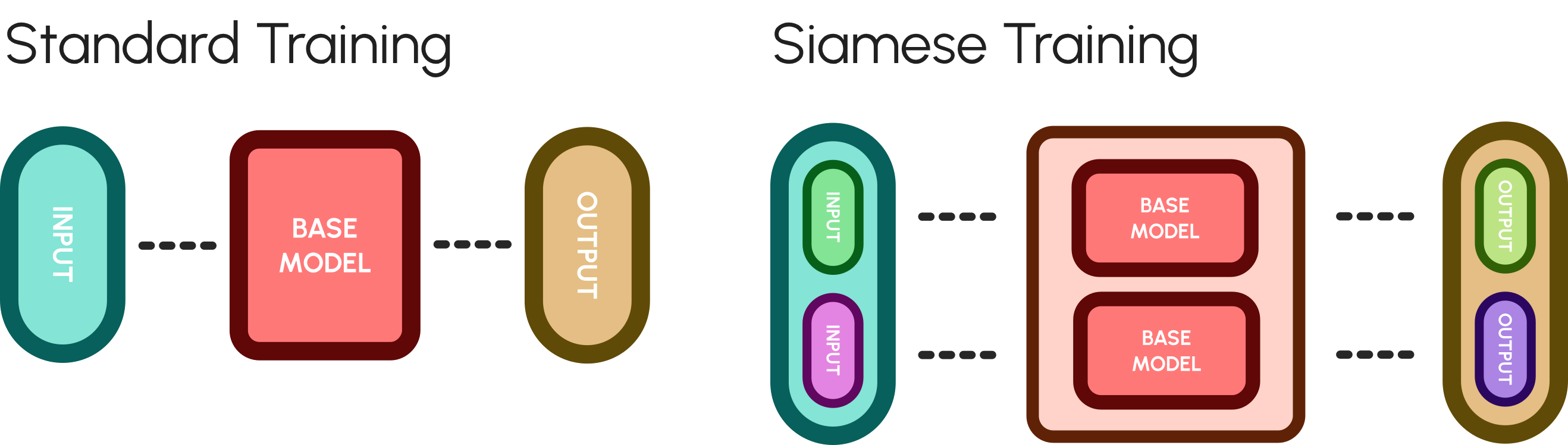
Symbolic knowledge is incorporated via data augmentation by generating synthetic samples based on logical rules that constrain the feature generation space.
The generation space has been reduced to minimize noise impact. The training pipeline is divided into two stages: the first performs standard training on the
knowledge-derived data, allowing the model to learn the underlying knowledge patterns; the second applies siamese training, enabling the model to learn from
the real data while remaining consistently guided by the symbolic knowledge throughout the entire process.
Since the method relies on data to convey the knowledge, any elements that are inconsistent with the symbolic rules - i.e., samples that satisfy the logical
thresholds but produce contradictory outputs - are removed to prevent confusion during training.
RESULTS
The method proved to be highly effective, standing out as the only approach among the existing tested methods that was able to improve balanced accuracy. In addition, it provided a significant enhancement in robustness when the data were subjected to perturbations. Indeed, to assess the contribution that the injection methods could offer in terms of robustness to the uneducated network, tests were conducted under increasing levels of data perturbation using different strategies. Perturbations such as Label Flipping, Data Dropping, and Feature Noise were applied. The following table highlights the performance improvements achieved by the Siamese method compared to both the other injection methods and the baseline uneducated network.
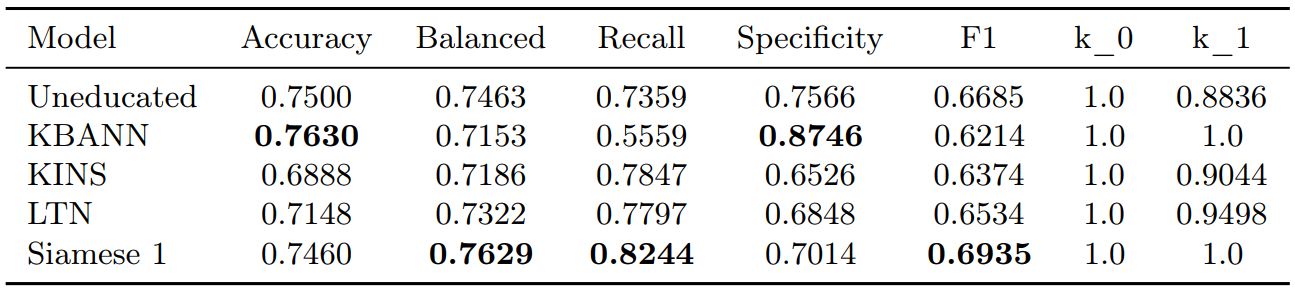
The only other method that showed comparable robustness was KBANN; however, this is largely due to the fact that the network generated by KBANN is very small and rigidly built upon the symbolic knowledge, which results in limited learning capacity and poor generalization. In contrast, STI relies on a generic neural network with arbitrary complexity, allowing for greater expressiveness, adaptability, and the ability to generalize beyond the injected knowledge. To improve statistical relevance, performance was evaluated on two datasets: Pima Indians Diabetes and Breast Cancer Wisconsin. The Pima Indians Diabetes dataset is used to distinguish diabetic patients from non-diabetic individuals based on diagnostic measurements, while the Breast Cancer Wisconsin dataset aims to classify tumors as malignant or benign based on various cellular features.
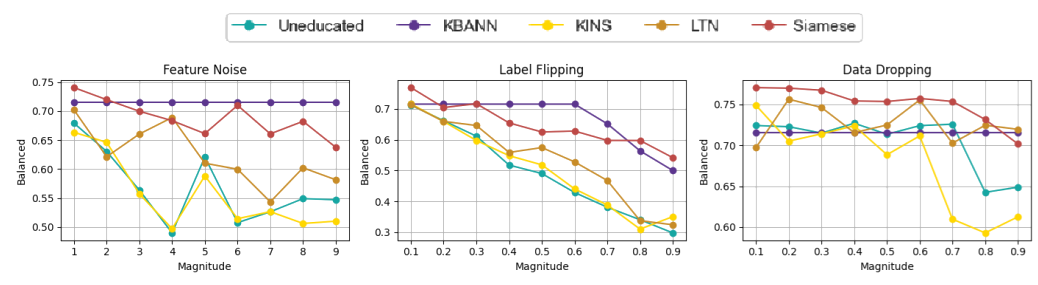 Fig. 1. Balanced accuracy of the methods as a function of perturbation magnitude on the Pima Indians Diabetes dataset.
Fig. 1. Balanced accuracy of the methods as a function of perturbation magnitude on the Pima Indians Diabetes dataset.
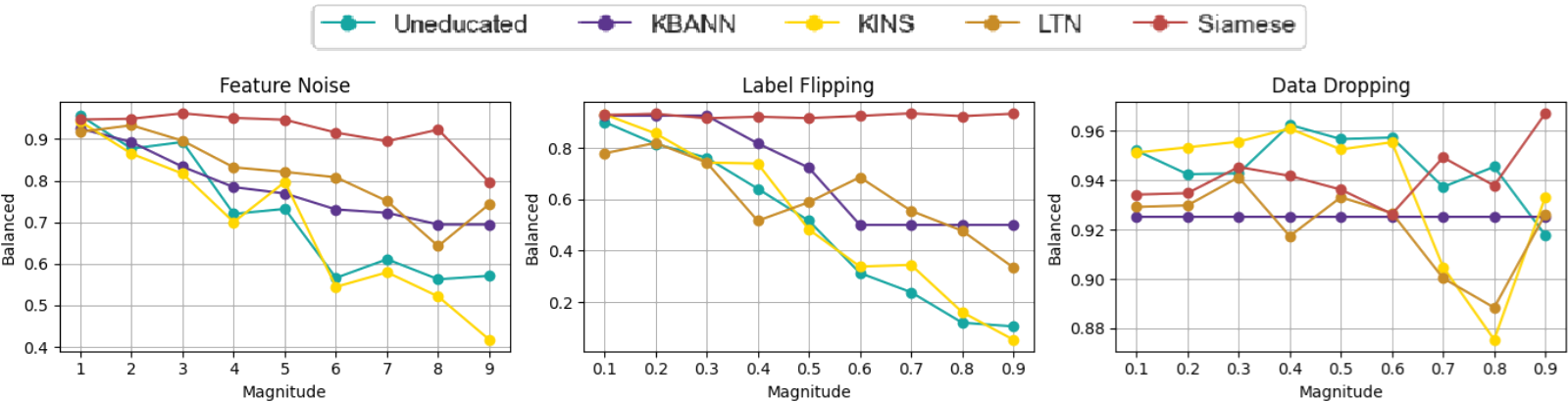 Fig. 2. Balanced accuracy of the methods as a function of perturbation magnitude on the Breast Cancer Wisconsin dataset.
Fig. 2. Balanced accuracy of the methods as a function of perturbation magnitude on the Breast Cancer Wisconsin dataset.
MORE
If you want to learn more, checkout my thesis.
Read my Thesis